工作原理
本节会尽可能简单明了地介绍 bili-sync 的工作原理,让用户了解程序的整体执行过程。
b 站的视频结构
在了解程序工作原理之前,我们需要先对 b 站视频的组织结构有一个大概的了解。简单来说:
- 收藏夹、稍后再看、视频合集、视频列表等结构都是由一系列视频构成的列表;
- 每个视频都有唯一的 bvid,包含了封面、描述和标签信息,并包含了一个或多个分页;
- 每个分页都有一个唯一的 cid,包含了封面、视频、音频、弹幕。
为了描述方便,在后文会将收藏夹、稍后再看这类结构统称为 video source,将视频称为 video,将分页称为 page。不难看出这三者有着很明显的层级关系:video source 包含若干 video,video 包含若干 page。
一个非常容易混淆的点是视频合集/视频列表与多页视频的区别:
NOTE
这两张图中,上图是视频合集,下图是多页视频。这两者在展示上区别较小,但在结构上有相当大的不同。结合上面对 b 站视频结构的介绍,这个区别可以简单总结为:
视频合集是由多个仅包含单个 page 的 video 组成的 video source;
多页视频是由多个 page 组成的 video。
这说明它们是处于两个不同层级的结构,因此程序对其的处理方式也有着相当大的不同。
与 EMBY 媒体库的对应关系
EMBY 的一般结构是: 媒体库 - 文件夹 - 电影/电视剧 - 分季/分集,方便起见,我采用了如下的对应关系:
- 文件夹:对应 b 站的 video source;
- 电视剧:对应 b 站的 video;
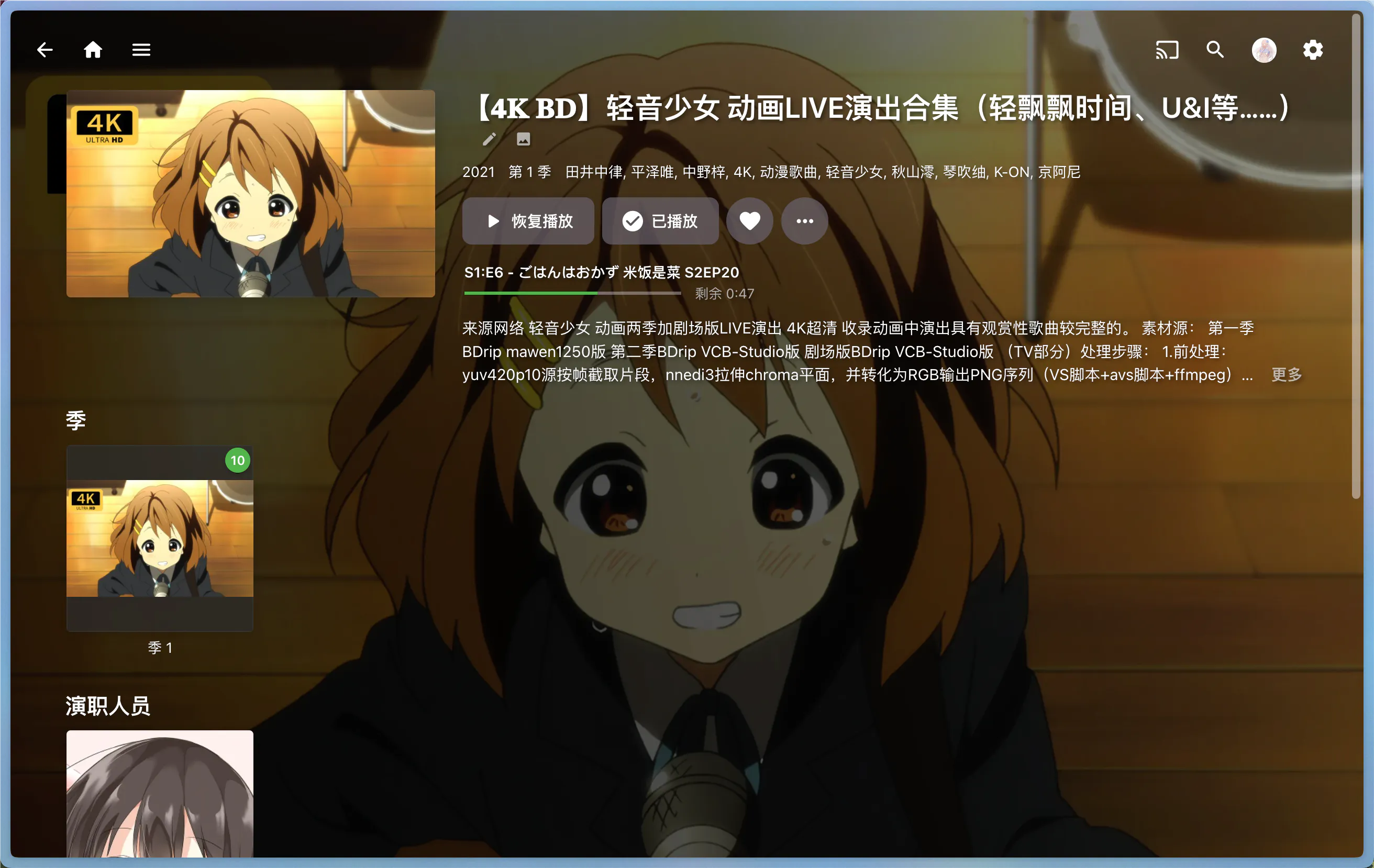
- 第一季的所有分集:对应 b 站的 page。
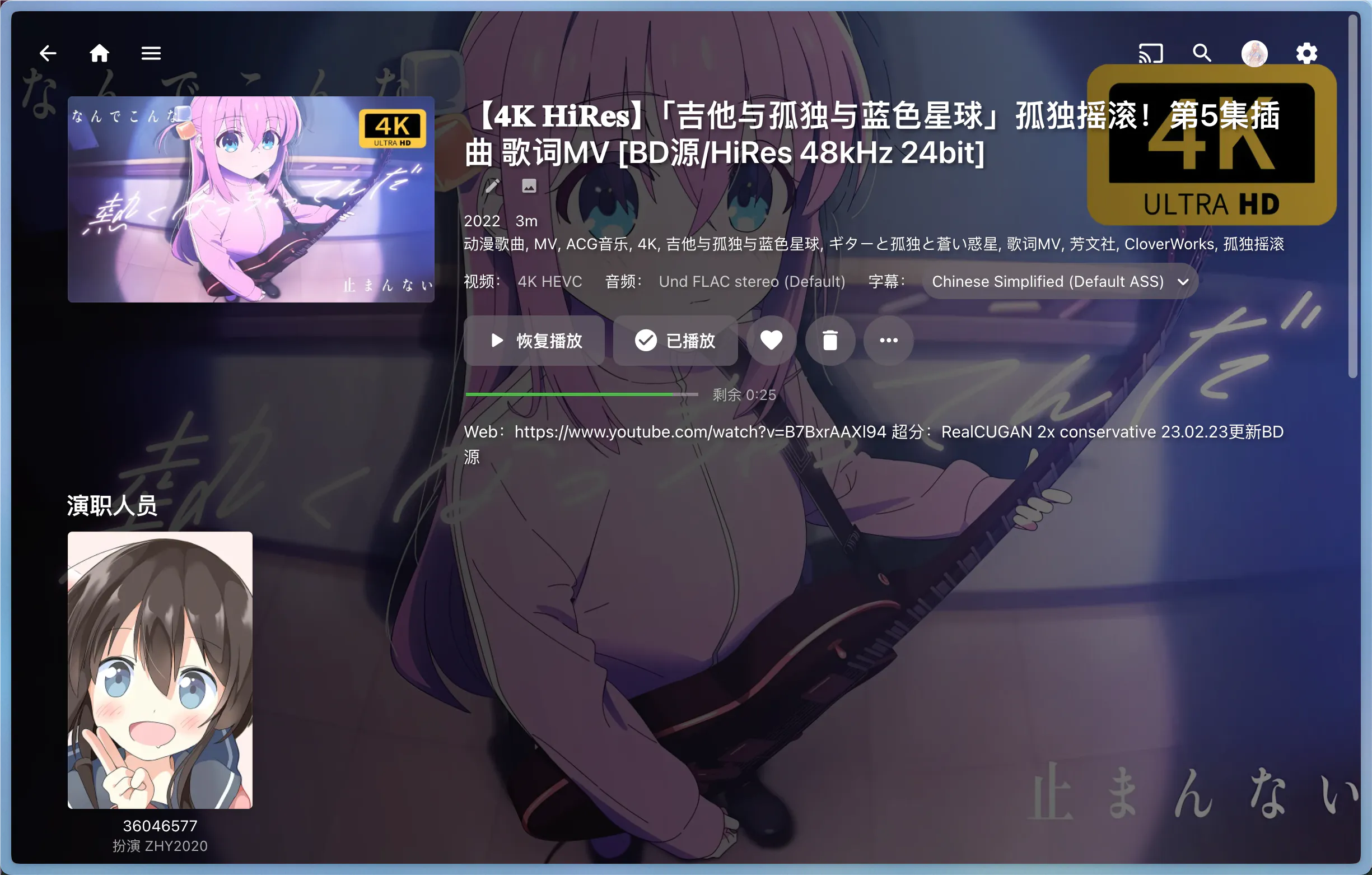
特别的,当 video 仅有一个 page 时,为了避免过多的层级,bili-sync 会将 page 展开到第二层级,变成与电视剧同级的电影。
因此,需要将媒体库类型设置为“混合内容”以支持在同个媒体库中同时显示电视剧与电影。
单 page 的 video
多 page 的 video
数据库设计
NOTE
可以前往此处实时查看当前版本的数据库表结构。
既然拥有着明显的层级关系,那数据库表就很容易设计了。为了简化实现,程序没有额外考虑单个 video 被多个 video source 引用的情况(如一个视频同时在收藏夹和稍后再看中)。而是简单的将其设计为了不交叉的层级结构。
video source 表
从上面的介绍可以看出,video source 并不是一个具体的结构,而是拥有多种实现的抽象概念。我选择将其特化实现为多张表:
- favorite:收藏夹;
- watch_later:稍后再看;
- collection: 视频合集/视频列表;
- ....
video 表
video 表包含了 video 的基本信息,如 bvid、标题、封面、描述、标签等。此外,video 表还包含了与 video source 的关联。
具体来说,每一种 video source 都在 video 表中有一个对应的列,指向 video source 表中的 id,如 favorite_id、collection_id 等。接下来将这些键与 video 的 bvid 绑在一起建立唯一索引,就可以保证在同一个 video source 中不会有重复的 video。
page 表
page 表包含了 page 的基本信息,如 cid、标题、封面等。与 video 类似但更简单,page 表仅包含了与 video 的关联。
执行过程
初始化
程序启动时会读取配置文件、迁移数据库、初始化日志等操作。如果发现需要的文件不存在,程序会自动创建。
扫描 video source 获取新视频
WARNING
b 站实现接口时为了节省资源,通过 video source 获取到的 video 列表通常是分页且不包含详细信息的。
程序会扫描所有配置文件中包含的 video source,获取其中包含的 video 的简单信息并填充到数据库。在实现时需要避免频繁的全量扫描。
具体到 bili-sync 的实现中,每个 video source 都有一个 latest_row_at 列,用于记录处理过的最新视频时间。程序在请求接口时会设置按时间排序,确保新视频位于前面。排序依据的时间根据 video source 的类型而定:收藏夹按收藏时间,投稿按照投稿时间...
拉取过程会逐页请求,程序会不断将获取到的视频保存到数据库中,直到发现第一个小于等于 latest_row_at 的视频时停止。接着将 latest_row_at 更新为最新的视频时间。
填充 video 详情
将新增视频的简单信息写入数据库后,下一步会填充 video 详情。正如上文所述:通过 video source 获取到的 video 列表通常是不包含详细信息的,因此需要额外的请求来填充这些信息。
这一步会筛选出所有未完全填充信息的 video,逐个获取 video 的详细信息(如标签、包含的 page 等)并填充到数据库中。
在这个过程中,如果遇到 -404 错误码则说明视频无法被正常访问,程序会将该视频标记为无效并跳过。
下载未处理的视频
经过上面处理后,数据库中已经包含了所有需要的 video 和 page 信息,接下来只需要筛选其中“未完全下载”、“成功填充详细信息”的所有视频,并发下载即可。程序在 video 层级最多允许 3 个任务同时下载,page 层级最多允许 2 个任务同时下载。
数据库中的 status 字段用于标记 video 和 page 的下载状态,视频的各个部分(封面、视频、nfo 等)包含在 status 的不同位中。程序会根据 status 的不同位来判断视频的下载状态,以此来决定是否需要下载。
如果某些部分下载失败,status 字段会记录这些部分的失败次数,程序会在下次下载时重试。如果重试次数超过了设定的阈值,那么视频会被标记为下载失败,后续直接忽略。
此处程序对风控做了额外的处理,一般风控发生时接下来的所有请求都会失败,因此程序检测到风控时不会认为是某个视频下载失败,而是直接终止 video source 的全部下载任务,等待下次扫描时重试。